New Tool Crowdsources Human Intelligence for Biological Research
As of Yesterday, Researchers Have a New Tool to Tap an Underutilized Resource in Life Science: Crowdsourcing
Scientists now have the ability to label cell parts in bright fluorescent colors, render tissue slices in high-definition photos and use video to monitor animal behavior down to the milliseconds. After capturing such images, researchers can analyze them to gain new insights on everything from basic cell structure to cancer diagnostics. Though image analysis is an increasingly powerful tool in the life sciences, there’s one problem: far too many images need to be analyzed.
Biologists are drowning in a sea of cellular photoshoots, and because they’re so drenched in such data, their experiments proceed less efficiently. Nothing gums up the scientific process like having 10,000 images to label.
To address this problem, a team led by researchers at UC San Francisco, the Chan Zuckerberg Biohub, and IBM have launched Quanti.us – a user-friendly website designed to recruit thousands of fresh eyes to look over scientific images. A paper describing the tool was published July 31 in Nature Methods.
Nowadays, biology and health science researchers can easily capture thousands of high-resolution images of everything from single protein molecules to crawling cancer cells. To revise the old saying, a picture is worth 1,000 data points, but someone still has to analyze them. Scientists themselves often don’t have the bandwidth to pore over thousands of images efficiently, and computer algorithms aren’t always refined enough to do the work for them.
The researchers teamed up with Joe Mornin, a technology lawyer and software engineer, to build Quanti.us on the back of Amazon’s Mechanical Turk service, which gives users access to a ready-and-waiting workforce of so-called “Turkers.” Quanti.us makes it simple for scientists to upload images, recruit workers, and provide instructions for each of their specific tasks. The site comes equipped with built-in annotation tools that allow Turkers to mark up images quickly and easily.

Zev Gartner, PhD, Associate Professor, Department of Pharmaceutical Chemistry.
“Humans are hardwired for image recognition and categorization,” said Alex Hughes, PhD, assistant professor of bioengineering at the University of Pennsylvania, who worked on Quanti.us as a postdoc in the UCSF lab of Zev Gartner, PhD.
There are thousands of human workers willing to analyze images on behalf of researchers through Mechanical Turk, explained Gartner, associate professor of pharmaceutical chemistry at UCSF, “but there was no simple mechanism to bring those people to bear on issues that biomedical researchers care about. Further, it wasn’t clear if Turkers would be able to provide accurate analyses.”
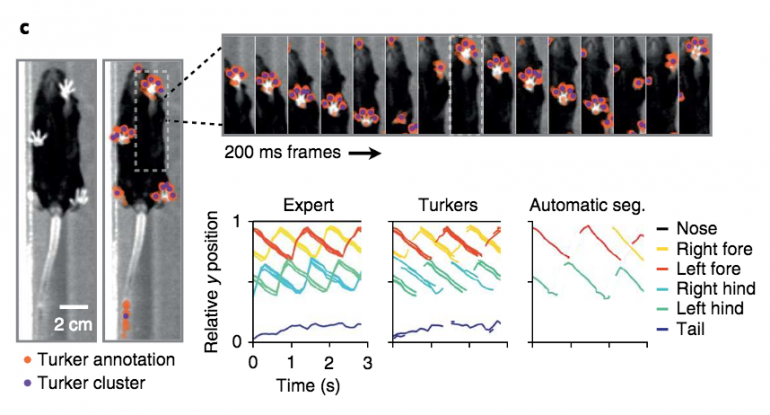
The assignments might include counting moving molecules in a cell, following moving cells in a tissue, or tracking the movement of mice on treadmills. Surprisingly, for existing computer algorithms, these tasks can be intractable, but given straightforward instructions, untrained humans complete them easily.
To put the “wisdom of crowds” to the test, Hughes, Gartner and the research team compared the Turkers’ accuracy to resident scientific experts at UCSF. They found that the averaged results from three to five Turkers were as accurate as the results from a single expert—sometimes they were more accurate.
“Different individuals, including experts, tend to make mistakes for different reasons,” said Gartner. “These mistakes tend to cancel out if you average results from multiple people.”
The researchers see the launch of their website as an opportunity for life scientists to outsource some of their most challenging and time-consuming work, cheaply and efficiently. They are also excited to engage non-scientists in the scientific process, challenging the notion that science can only be performed by a small, select percentage of society.
“Besides being a resource for their own data analysis efforts,” Hughes said, “we think that many Quanti.us users will end up using it in the classroom and elsewhere for outreach and education.”
The team went on to collaborate with colleagues at the IBM Almaden Research Center to create new machine learning algorithms with Quanti.us data, and they see a future where scientists mix and match designer algorithms for specific research questions, freeing them from the drudgery of clicking on thousands of images.
“We’re starting to see machine learning creep into scientific discovery,” Hughes said, “and we think that the massive amount of annotations that Quanti.us users can get for very specific problems will have a huge impact.”